1.PySpark
PySpark 是 Apache Spark 的 Python API,允许数据科学家和开发人员使用 Python 语言编写 Spark 应用程序。PySpark 提供了对 Spark 核心功能(如 RDD、DataFrame 和 MLlib)的访问,同时还提供了与 Python 生态系统中的其他库(如 NumPy、pandas 和 scikit-learn)的集成。
使用 PySpark,可以处理大规模数据集,进行分布式计算,执行复杂的数据转换和聚合操作,构建机器学习模型,以及与其他大数据和机器学习工具进行交互。
1.1 pyspark组件
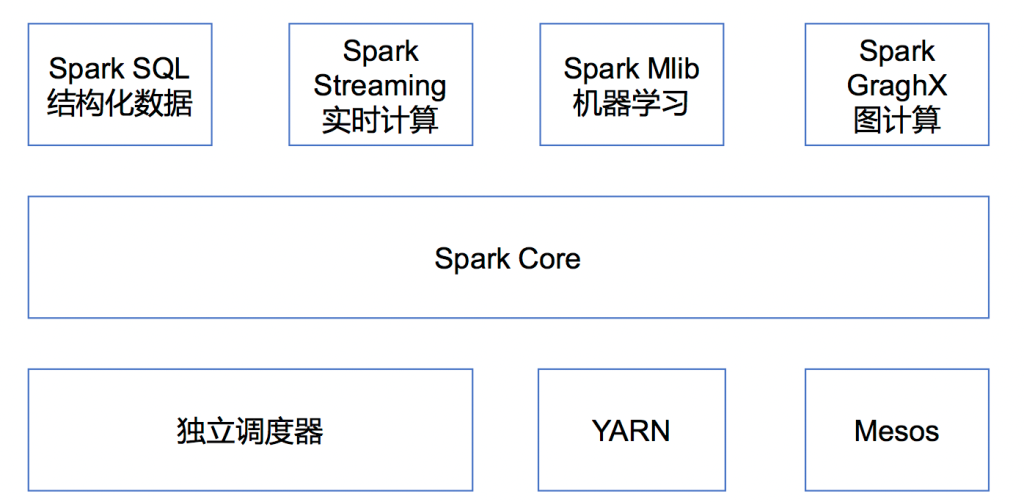
RDD (Resilient Distributed Dataset): RDD 是 Spark 的基本数据结构,代表一个不可变的、分布式的对象集合。RDD 允许在集群上进行并行计算。RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
DataFrame: DataFrame 是 Spark SQL 的核心数据结构,它提供了一个分布式的数据表格,可以包含多种类型的数据。DataFrame API 提供了类似于 SQL 的方式来查询和操作数据。
Spark SQL: Spark SQL 允许使用 SQL 语句查询 DataFrame。它还提供了 DataFrameReader 和 DataFrameWriter 接口,用于从各种数据源读取数据和将数据写入各种数据源。
MLlib: MLlib 是 Spark 的机器学习库,提供了各种机器学习算法和工具,包括分类、回归、聚类、协同过滤和降维等。
GraphX: GraphX 是 Spark 的图处理库,允许您创建和操作大规模图结构数据。
Structured Streaming: Structured Streaming 是 Spark 的流处理库,允许对实时数据流进行高效、可扩展和容错的处理。
1.2 运行模式
本地运行模式:
这是Spark的默认运行模式,适用于在本地机器上进行开发和测试。在本地模式下,Spark将运行在单个线程上,不需要启动集群。这种模式适用于小规模数据集的处理和调试。您可以通过控制台使用命令pyspark --master local[4]来启动本地运行模式,其中local[4]表示使用四个逻辑CPU核心。此外,如果您希望使用Python 3环境,可以通过设置环境变量PYSPARK_PYTHON=python3来实现。
集群运行模式:
当需要处理大规模数据集或需要更高的计算能力时,通常会选择集群运行模式。在集群模式下,Spark会在一个或多个节点上分布式地运行,以充分利用集群的计算资源。集群运行模式有多种,其中Standalone模式是只有或主要运行Spark的集群。在这种模式下,您需要先启动Master节点,然后提交Spark应用程序到集群进行执行。
2.基本使用
2.1 dataframe与rdd介绍
2.1.1 DataFrame
DataFrame的结构类似于传统数据库的二维表格,每列都带有名称和类型,这种结构信息使得Spark SQL能够对DataFrame进行针对性的优化,从而提升运行时效率。
DataFrame可以从许多数据源中创建,例如结构化文件、外部数据库和Hive表等。此外,与Hive类似,DataFrame也支持嵌套数据类型,如struct、array和map。
2.1.2 rdd
RDD(Resilient Distributed Dataset,弹性分布式数据集)是Spark中的核心概念之一,代表一个不可变、只读的分布式对象集合。每个RDD都被分为多个分区,这些分区可以分布在集群的不同节点上进行并行计算。RDD的主要特点包括不可变性、分区和容错性。
2.1.3 关系与区别
在Spark中,DataFrame和RDD(Resilient Distributed Dataset,弹性分布式数据集)都是用于处理分布式数据的重要数据结构,但它们之间存在一些关键的区别和联系。
首先,RDD是Spark中最基础的数据抽象,它是一个不可变、可分区、元素可以并行计算的集合。RDD只包含数据本身,没有定义数据的结构信息。这意味着在使用RDD时,用户需要手动处理数据的序列化和反序列化,以及数据的分区和计算逻辑。
相比之下,DataFrame是Spark SQL中引入的一个更高层次的数据抽象,它基于RDD但提供了更多的功能和优化。DataFrame除了包含数据本身外,还记录了数据的结构信息,即schema。这个schema定义了每一列的名称和类型,使得Spark能够更好地理解数据的结构,并据此进行优化。
由于DataFrame带有元数据schema,它提供了类似于传统关系型数据库表格的操作方式,可以使用SQL语句进行查询。这使得数据科学家和开发人员能够更方便地处理和分析数据,而无需编写复杂的代码。
2.2 使用
2.2.1 创建dataframe
from pyspark.sql import SparkSession
# 初始化SparkSession
spark = SparkSession.builder.appName("test").getOrCreate()
# 定义数据
data = [(1, "John Doe"), (2, "Jane Doe")]
schema = ["id", "name"]
# 创建RDD
rdd = spark.sparkContext.parallelize(data)
# 将RDD转换为DataFrame
df = spark.createDataFrame(rdd, schema)
# 显示DataFrame的内容
df.show()将pandas的dataframe转为spark df:
import pandas as pd
from pyspark.sql import SparkSession
# 初始化SparkSession
spark = SparkSession.builder.appName("example").getOrCreate()
# 创建一个Pandas DataFrame
pandas_df = pd.DataFrame({
'id': [1, 2],
'name': ['John Doe', 'Jane Doe']
})
# 将Pandas DataFrame转换为Spark DataFrame
spark_df = spark.createDataFrame(pandas_df)
# 显示Spark DataFrame的内容
spark_df.show()2.2.2 读取文件
2.2.2.1 JOSN文件
如json数据文件里:
{"user_id_2":"E9qhpVHANpl4EKXpREKhSA","count":3}使用pyspark读取,并操作df,将user_id与count放入不同的数组:
spark = SparkSession.builder \
.appName("read_json") \
.master("local") \
.getOrCreate()
d_all=dict()
file='file.json'
df=spark.read.json(file)
sdf=df.select('user_id_2','count').limit(6)
sdfs=sdf.collect()
user_id = []
count = []
json_content = []
for sdf_ in sdfs:
user_id.append(sdf_.asDict().get('user_id_2'))
count.append(sdf_.asDict().get('count'))
json_content.append(user_id)
json_content.append(count)
d_all[(file.split('.')[0])]=json_content2.2.2.2 csv文件
#csv文件中首行一般为数据的列名称,header设为True则不会把名称设为数据
spark.read.csv('dataset/wordcloud.csv',header=True)2.2.2.3 读取文本与分割
from pyspark.sql import SparkSession
# 初始化SparkSession
spark = SparkSession.builder.appName("read_txt_file").getOrCreate()
# 指定txt文件的路径
txt_file_path = "path_to_your_txt_file.txt"
# 读取txt文件
df = spark.read.text(txt_file_path)
# 显示DataFrame的内容
df.show()
# 显示DataFrame的schema
df.printSchema()分割文本:
from pyspark.sql.functions import split, col
# 使用逗号作为分隔符分割每行文本
df_split = df.withColumn("split_values", split(col("value"), ","))
# 显示包含分割后值的DataFrame
df_split.show(truncate=False)2.3 Mysql数据库的读写
下面是mysql数据库的读写工具类,模块可以被引用,使用之前需要将mysql连接jar包放入pyspark的jars目录:
from pyspark.sql import SQLContext, SparkSession
'''
@Author: lijun
@Date: 2024.3.10
@Description:pyspark读写mysql数据库的接口
'''
class SparkRWMysql:
def __init__(self):
self.spark = SparkSession. \
Builder(). \
appName('sql'). \
master('local'). \
getOrCreate()
# mysql 配置(需要修改)
self.prop = {'user': 'scu21',
'password': 'G5iCrD8DNbeG',
'driver': 'com.mysql.jdbc.Driver'}
self.url = 'jdbc:mysql://114.115.206.93:3306/scu?useSSL=false&useUnicode=true&characterEncoding=UTF-8'
def read(self, table_name):
# 读取表
data = self.spark.read.jdbc(url=self.url, table=table_name, properties=self.prop)
return data
def write(self, table_name, df):
# 写入数据库
df.write.jdbc(url=self.url, table=table_name, mode='append', properties=self.prop)
def read(table_name):
return SparkRWMysql().read(table_name)
def write(table_name, df):
try:
SparkRWMysql().write(table_name, df)
return True
except Exception as e:
print(e)
return False2.4 pyspark连接集群
需要将下面蓝色文件加入到项目:
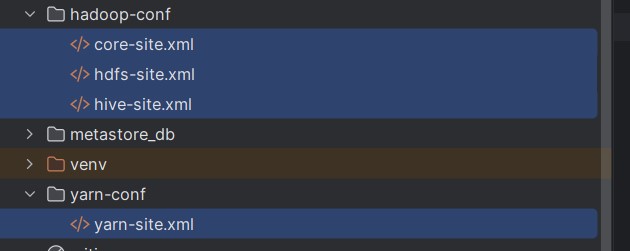
并修改连接mysql信息,添加hosts文件的ip映射,需要安装hadoop并添加环境变量,安装java环境,及python与hadoop对应的版本。
from pyspark import SparkConf, HiveContext
import os
from pyspark.sql import SparkSession
class SparkSessionBase:
SPARK_APP_NAME = None
SPARK_URL = "yarn"
SPARK_EXECUTOR_MEMORY = "6g"
SPARK_DRIVER_MEMORY = "4g"
SPARK_EXECUTOR_CORES = 6
SPARK_EXECUTOR_INSTANCES = 10
ENABLE_HIVE_SUPPORT = False
def _create_spark_session(self):
if not os.environ.get('HADOOP_HOME'):
os.environ['HADOOP_HOME'] = 'D:\\File\\hadoop-2.7.7'
if not os.environ.get('HADOOP_CONF_DIR'):
os.environ['HADOOP_CONF_DIR'] = 'hadoop-conf'
if not os.environ.get('YARN_CONF_DIR'):
os.environ['YARN_CONF_DIR'] = 'yarn-conf'
os.environ["HADOOP_USER_NAME"] = "os"
conf = SparkConf()
settings = (
# 设置启动的spark的app名称,没有提供,将随机产生一个名称
("spark.app.name", self.SPARK_APP_NAME),
# 设置该app启动时占用的内存用量,默认2g
("spark.executor.memory", self.SPARK_EXECUTOR_MEMORY),
("spark.driver.memory", self.SPARK_DRIVER_MEMORY),
# spark master的地址
("spark.master", self.SPARK_URL),
# 设置spark executor使用的CPU核心数,默认是1核心
("spark.executor.cores", self.SPARK_EXECUTOR_CORES),
# 设置spark作业的Executor数量,默认为两个
("spark.executor.instances", self.SPARK_EXECUTOR_INSTANCES)
)
conf.setAll(settings)
if self.ENABLE_HIVE_SUPPORT:
return SparkSession.builder.config(conf=conf).enableHiveSupport().getOrCreate()
else:
return SparkSession.builder.config(conf=conf).getOrCreate()2.5 相关常用函数
- withColumn()与lit():
#df添加名为count、值都为2的列 df.withColumn("count", lit('2')).show() - drop:删除列
df.drop("column1").show() - distinct() - 去除 DataFrame 中的重复行。
- rdd:map() - 对 RDD 中的每个元素应用函数。
rdd.map(lambda x: x * 2).collect() - filter() - 过滤 RDD 中的元素。
rdd.filter(lambda x: x > 10).collect() - union() - 合并两个 RDD。
union_rdd = rdd1.union(rdd2) - intersection() - 返回两个 RDD 的交集。
intersection_rdd = rdd1.intersection(rdd2)